Peeking Under the Hood of a Running Bitcoin Node
I’ve been running a Bitcoin full node for over a year now, but the only insight I ever had into what it was doing was how many connections it maintained and how much bandwidth it was using. In my quest to gain a better understanding of the Bitcoin network, several weeks ago I forked the Bitcoin Github repository and began modifying it to collect statistics about the internal operations of the full node. There are still many other statistics I’d like to collect, but here are some preliminary results. In order to attempt to capture a more accurate representation of the network, I modified my node to maintain at least 500 peer connections, which is about 5% of the total nodes on the network and is the limit that my home broadband’s upstream can support.
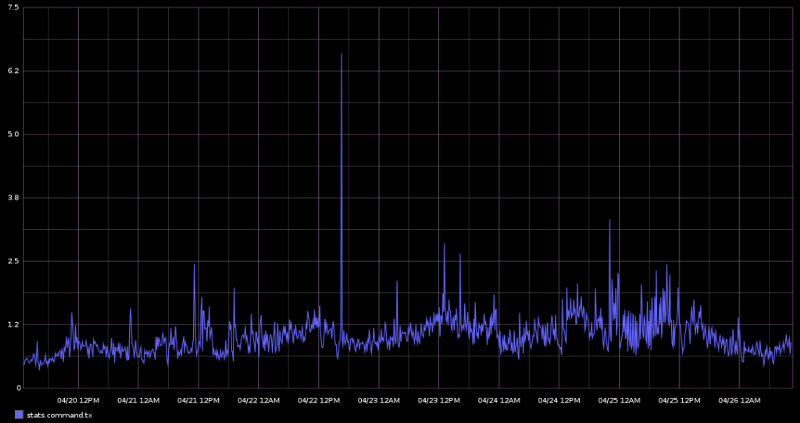
We’ll start off with a very simple example: transactions. As we can see here, my node is only seeing about one unique transaction per second. This is in line with stats collected by Blockchain.info.
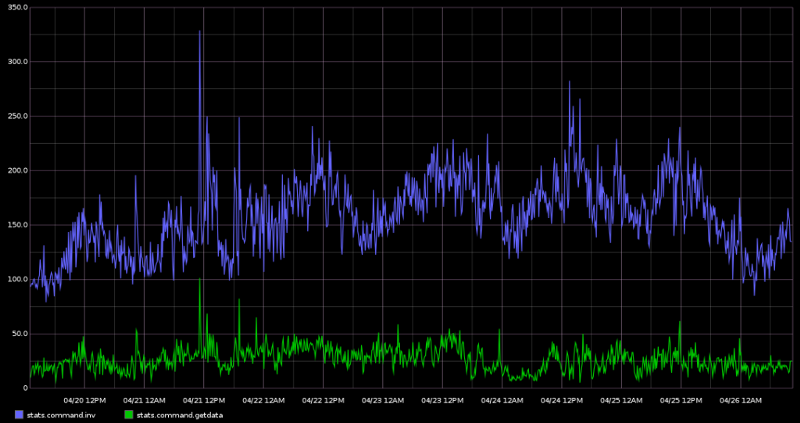
Next is a graph that gives us a general idea of the volume of messages being sent throughout the network mesh. An “inv” message is a compact message received from a peer that informs us that the peer has received a piece of data such as a transaction or block, and is thus inviting our node to request the data from it. If the inv message we receive is for a piece of data our node does not have, it will respond to that peer with a “getdata” request. Once we have the new piece of data, we will then send out inv messages to the rest of our peers letting them know that we have the data and they are welcome to request it from us. This is the fundamental design of how data propagates throughout the Bitcoin network. Thus the graph below shows us the volume of announced data we’re seeing from our peers vs the volume of data our peers are requesting from us.
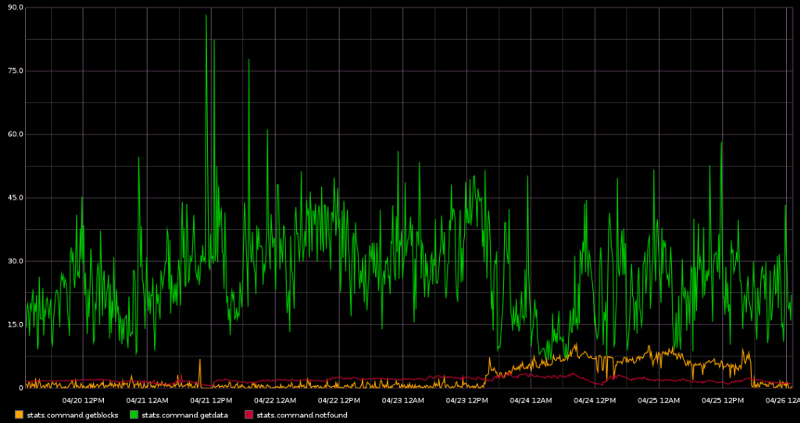
Now, scaling down further with the “getdata” messages as a reference point, we can observe the “getblocks” and “notfound” messages. My understanding is that “getblocks” messages are likely being sent from nodes that are out of sync with the blockchain and need to catch up. I wonder if the increase in getblocks messages on the 24th and 25th indicates that a decent number of new nodes were joining the network. I’m not sure what to take away from the “notfound” stats — it seems like this should be a rare occurrence because our node should only be requesting data from peers that explicitly told us (via an inv message) that they had the data available.
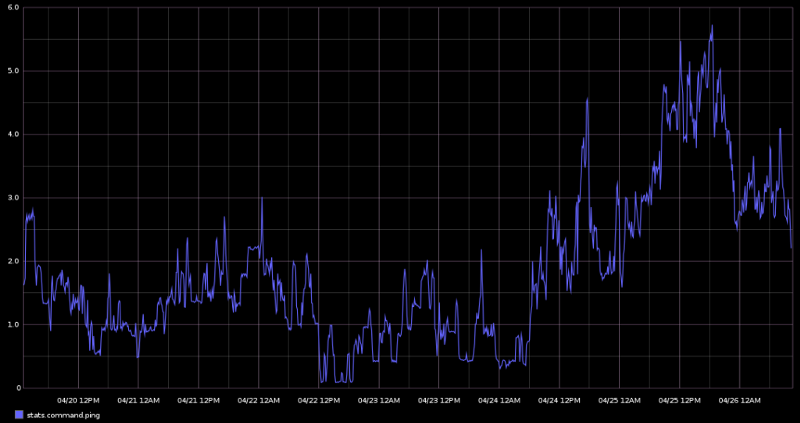
Next are the “ping” messages. These are essentially requests from our peers asking to see if our node is still on the network. This graph is not particularly interesting in and of itself, but what I do find interesting is that my node has not registered a single “pong” message for the entire duration that I have been monitoring it. After looking at the code, it appears that a node will only send a ping message if it has not sent any other messages to that peer in over half an hour. Perhaps I’m overlooking something, but the only explanation I can think of for this phenomenon would be that my node is staying busy enough relaying data that the only reason it would go for half an hour without sending a message to a peer is if the peer drops off of the network, thus none of the “ping” messages that are sent by my node ever receive a “pong” response.
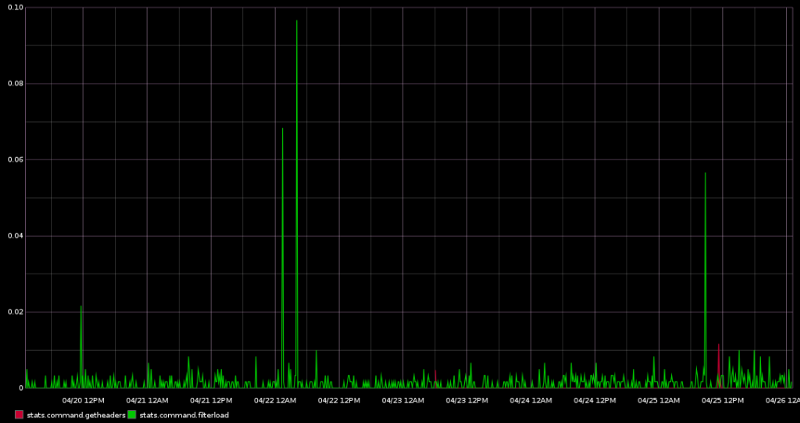
Here are the “filterload” requests which are from BIP037, which is meant to be used by SPV clients, AKA lightweight wallets. The other messages from BIP037, “filteradd,” “filterclear,” and “merkleblock,” were not seen at all over the course of the past month that my modified node has been running. Perhaps this is because these messages have not yet been implemented in any of the popular lightweight wallets? If you look closely, you can also see the “getheaders” requests which is another indication of SPV clients. It appears that the amount of traffic generated by SPV clients relative to full nodes is negligible, with an average of less than one request every couple minutes.
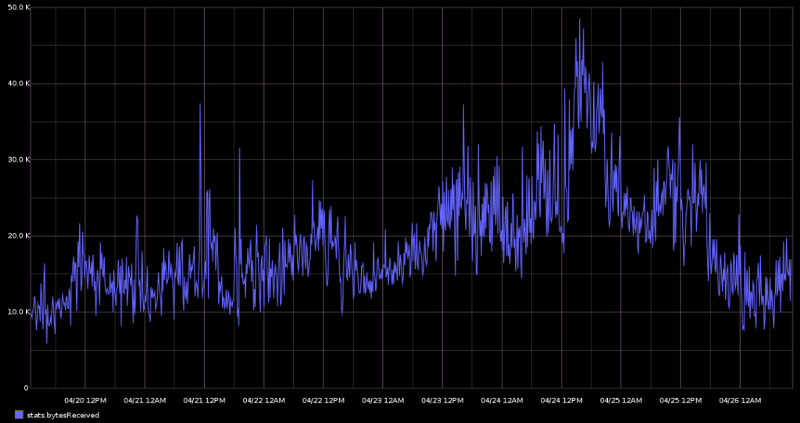
The next couple charts are good news, in my opinion. Here is the size of the incoming data being processed by my node. As we can see here, even with 500+ connected peers, the node never needs more than 50 KB/S of downstream bandwidth. This is because the vast majority of messages received by the node are “inv” messages, which are extremely small — only 40 bytes per message. The upstream bandwidth usage, however, is at least an order of magnitude higher.
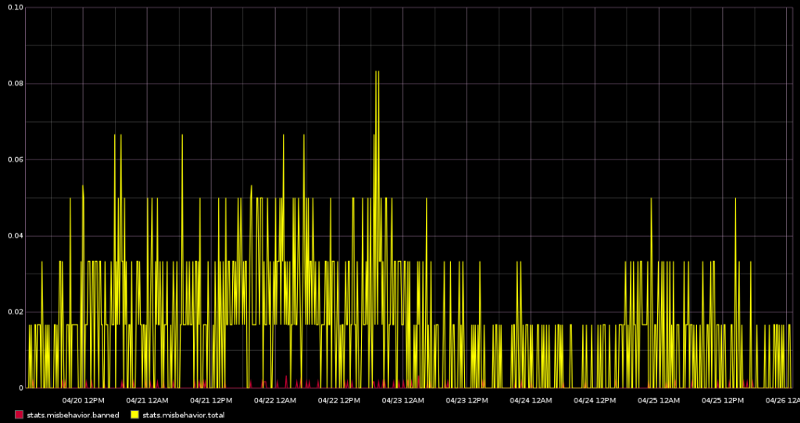
Finally, we observe known misbehavior by our peers on the network. The yellow line indicates logged misbehaviors, which means a peer node interacted with us in a manner outside the specifications of the protocol. The Bitcoin reference client has a number of rules by which it flags nodes as misbehaving. Different rules carry different penalties, many of which are weighted higher if the peer continues to break them in a manner that could be considered malicious / a denial of service attack. If a peer node’s penalties exceed a certain threshold, it will be banned. As we can see from the graph, misbehavior is generally a rare occurrence and even while maintaining 500+ connections, we only ban about 10 peers per day. If I recall correctly, peer bans only last for 24 hours, so it may very well be the same 10 misbehaving nodes that keep re-connecting and getting re-banned.
This first look at the internals of Bitcoin node message processing volume has given me a number of ideas for other metrics that may be helpful to collect, and in general has made me more confident about the health of the network. If you’re a Bitcoin node operator who is interested in monitoring your node in such a fashion, feel free to contact me. I hope to make a post in the near future in which I will release my open source Bitcoin fork and provide instructions for how to set it up to collect the statistics that it outputs.




