Is the Bitcoin Network Slowing Down?

For the past 4 years I have conducted annual full node syncing tests of every maintained Bitcoin implementation. This is primarily to see how well the various teams are doing in combating the relentlessly increase size of the blockchain.

But something weird happened during my 2021 testing - I observed unexplained slowdowns across the board that appeared to be network bottlenecks rather than CPU or disk I/O bottlenecks. These slowdowns disappeared when I re-ran my syncs while only requesting data from peer nodes on my local network.
Bcoin v2.2.0
On its first run, downloading blocks from publicly available peers:
- Reached block 655,000 in 40 hours 30 min. 85% slower than last year.
Syncing from a node on my local network did much better:
- Reached block 655,000 in 24 hours 9 min. 10% slower than last year.
Bitcoin Core v22
1st run took 6 hours 27 min to block 655,000. 13.5% slower than last year.
I thought perhaps it was because I had a wallet enabled, so I did a 2nd run with the wallet disabled, but it once again took exactly 6 hours 27 min. 13.5% slower than last year.
3rd run of v22: 6 hours 28 min to get to block 655,000. 13.5% slower than last year.
4th run of v0.21.2 took 7 hours 3 min to get to block 655,000. 24% slower than last year.
5th run of v0.21.2 but from a local network peer to block 655,000 took 5 hours 29 min - 12 min faster than my v0.21 test a year ago.
Suffice to say that these results are confusing. I'm on the same gigabit connection as last year and my bandwidth tests don't show it to be a bottleneck. So it looks like code performance increases made syncing about 10% faster, but something affecting the network has slowed it down by nearly 25%.
After discussing with Core maintainer Marco Falke, he suggested the culprit could be bad peers on the public network:
Syncing from the network obviously means that the weakest link might be outside your control. Two scenarios come to mind: First, you might have a peer that delivers blocks, but does so at a reduced speed. Second, you might have a peer that actively sabotages block relay by promising to send the block, but never follows up. This should cause slow-downs whenever the slow peer is the last one in the 1000 block download window.
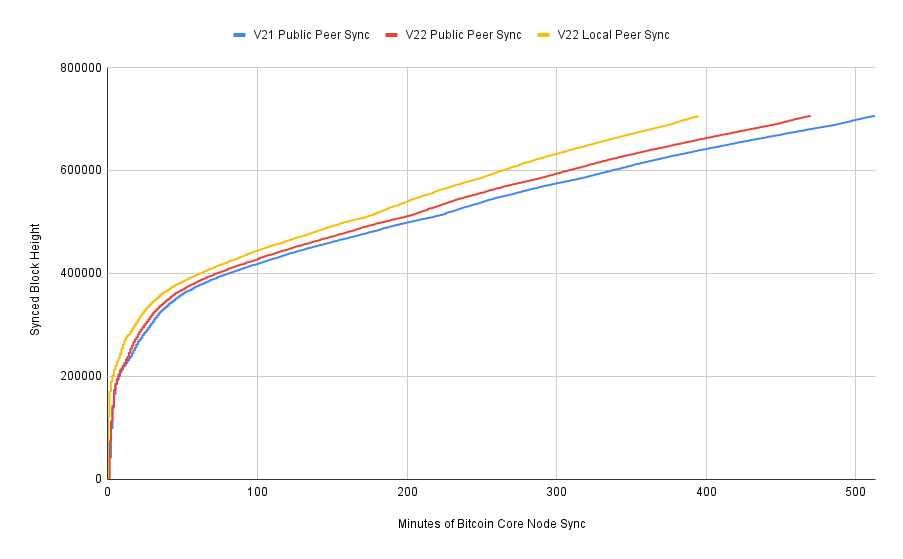
Charting Sync Performance
To try to determine where the slowdown is happening, I next took the sync logs from v21 and compared them to v22, resulting in the following chart. Here we can see that the slowdown is pretty uniform throughout the blockchain sync.
Malicious Peers?
During my first sync test of Gocoin it crashed while requesting a block from this peer due to receiving malformed block data. Under its services it advertised the NODE_NETWORK flag which means it should have all blocks available.
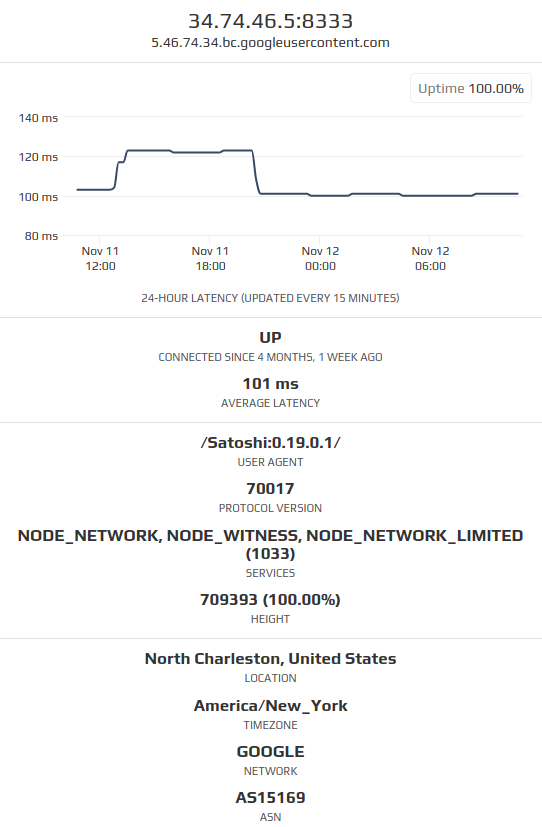
Note that this (google cloud hosted) node that served malformed block data existed in November 2021 but as of January 2022 it no longer exists. I haven't been able to find a pattern of other nodes acting in a similar fashion, but it's noteworthy because this is the only "obvious" maliciousness that I've observed during my testing.
Too Many Pruned Nodes?
out of all the addrs my node has _ever_ seen only 4% (1606/37639) of them (that may not actually be reachable/listening rn) have full block data
— Olaoluwa Osuntokun (@roasbeef) November 12, 2021
matches up w/ luke-jr's stats that take into account a wider set of nodes (w/ more history/data): https://t.co/cm2QL2uYLI
BIP 159 describes how nodes can advertise the NODE_NETWORK_LIMITED service bit to state that they are capable of serving the most recent 288 blocks. If a node has this service bit set but not the NODE_NETWORK bit set, you should assume it's a pruned node. Of course, it could be lying, but we'll discuss that later.
At time of writing 13,000 reachable nodes signal NODE_NETWORK and 14,000 signal NODE_NETWORK_LIMITED, leading me to believe that only 7% of reachable nodes are pruned. I think it's unlikely that this is the culprit of the network-wide slowdown.
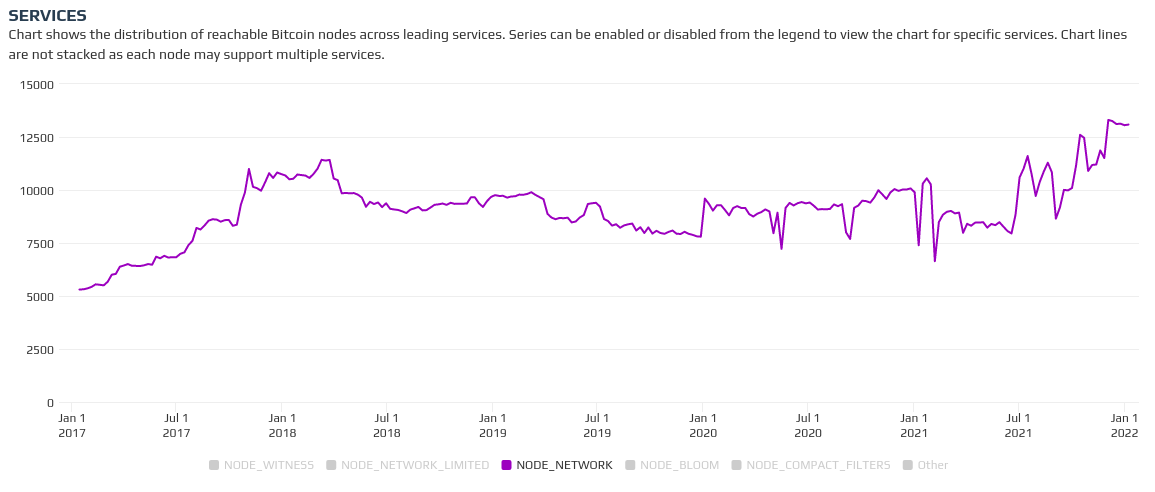
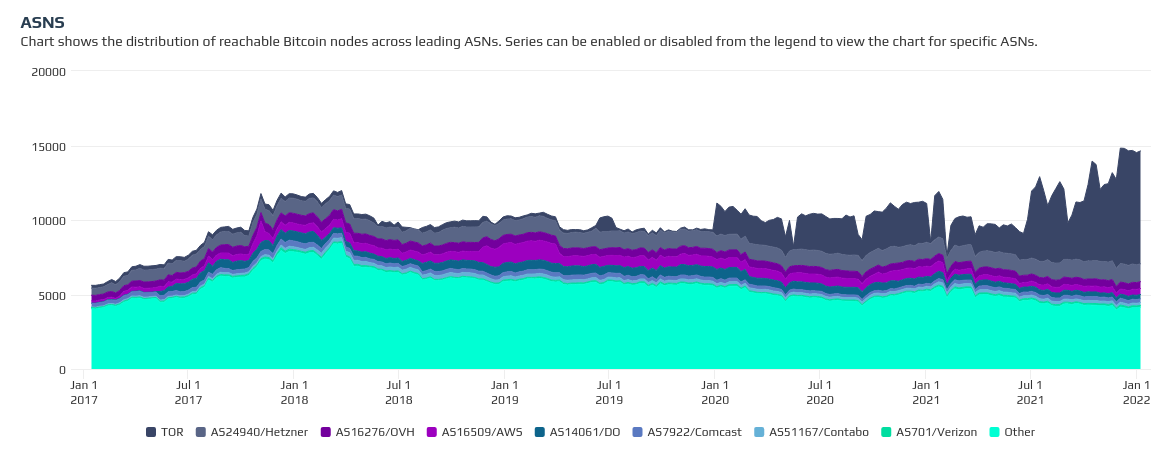
On the other hand, I do think it's noteworthy that while Bitnodes' total reachable node counts have been increasing, it's solely due to the influx of nodes on the tor network - IPV4 network nodes have actually been decreasing.
Slow Peers
Marco noted that an unresponsive peer could stall the downloading of a block. We can see on this StackExchange answer that Pieter Wuille notes during initial block download a node only requests a given block from 1 of its peers.
He also notes that a peer can hold a connection open and not respond for up to 15 minutes before your node will request the block from a different peer. If we consider that my v22 public network node sync takes 76 minutes longer than my v22 local network sync, that could be from as few a as half a dozen malicious peers stalling for 15 min each.
However, it turns out there's more nuance to this number than I originally understood. The 15 minute timeout only applies when your node is already at chaintip. During initial block download (IBD) there is actually a different timeout rule that gets triggered.
We can see here in Bitcoin Core code where the logic lies for detecting and disconnecting from a peer that is stalling our initial block download.

I kept the debug logs for all the syncs I ran during my tests and noted that each sync included this line about 10 times. But how long had these peers actually stalled our download? It turns out the BLOCK_STALLING_TIMEOUT is a mere 2 seconds.
Peer Latency
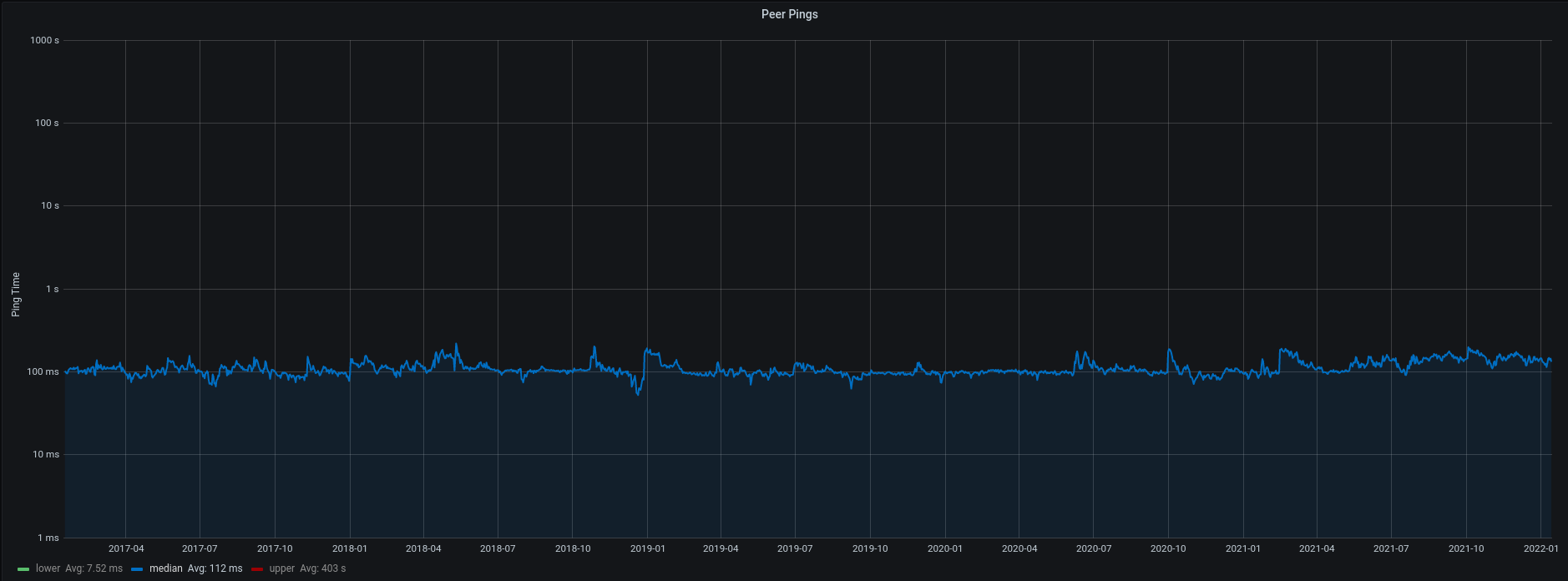
This isn't a chart that covers the entire network - just the ~120 peers connected to my own node, but my node hasn't seen any substantial deviation in the median ping time over the past 5 years.
Available Connection Slots
Another potential issue is how many full nodes have slots open? A default node has a max of 112 incoming connection slots. As I explained in great detail during the scaling debates, the claims that the Bitcoin network can scale orders of magnitude just with SPV (light client) users fail to take into account the additional resource burden placed on the full nodes that act as servers.

At time of writing Bitnodes is only reporting around 50% of reachable nodes as having available connection slots.
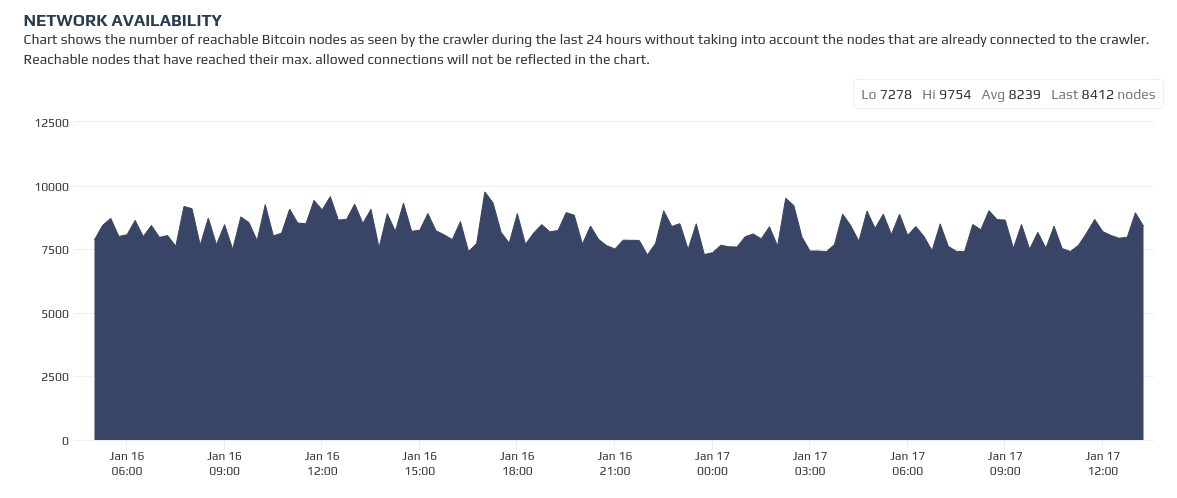
In my experience, nodes that manage to maintain 100% uptime for long periods of time tend to have their available connection slots saturated. My node at statoshi.info pretty much always has all 124 slots in use; the breakdown across different peer types is generally:
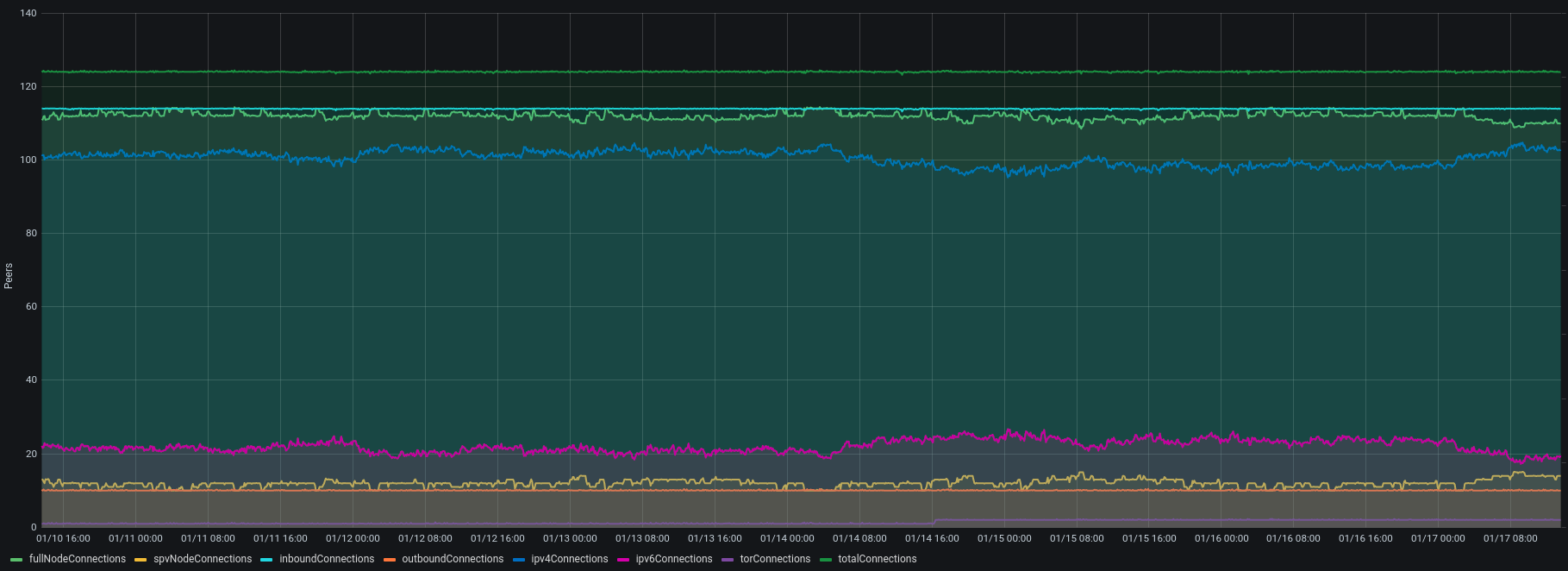
Full nodes: 110
SPV Clients: 14
IPV4: 103
IPV6: 19
tor: 2
On the bright side, anecdotally it doesn't look like light clients are saturating the network's connection slots. But that's just from the perspective of my own node.
Crawling the Network
Unfortunately it's not possible to figure out how full a remote node's connection slots are. The best we can do is try to connect and see whether or not the connection attempt is accepted. So I wrote this script to do just that. It downloads the latest list of reachable nodes from Bitnodes' API and then attempts to open a connection with each of them that are on the IPV4 network. On my first run I only opened a socket and did not send any actual p2p messages.
Reachable nodes: 5781
Unreachable nodes: 57
This was better than expected - only a 1% failure rate, which could easily be explained by those nodes being offline temporarily.
On the next run I went a bit deeper and actually sent a "version" message to see if I could get an intelligible response back from the peer. Nearly 7% failed to respond.
Reachable nodes: 5491
Unreachable nodes: 399
What Makes a Node Real?
At this point it may be worth noting that there is no such thing as "proof of full node" - that is, there's no way to know for sure if a remote peer to which you are connected is really a full node. It's always possible that it could be an emulator or proxy that just relays data from real full nodes. There's even a proof of concept project for that here:
 basil00
basil00Along a similar vein, it's worth noting that nodes may be counted multiple times by crawlers such as Bitnodes. For example, my node that powers statoshi.info actually gets counted 3 times - one for each network interface upon which it operates (IPV4, IPV6, tor.)
At time of writing, Bitnodes reports 5900 IPV4 nodes, 1250 IPV6 nodes, 7650 tor nodes. Assuming a scenario of max duplication across all networks then there may be as few as 7650 unique reachable nodes. Though it could be fewer if some of them are "pseudo nodes" as mentioned earlier.
Available Bandwidth
Finally, there's a question of actual bandwidth. Per Marco Falke's original suggestion, there could just be a lot of slow or even malicious peers on the network that deliver block data slowly or not at all. Thus my next round of tests involved requesting 10 (max size) blocks from each peer to see what the average throughput was. The raw data produced by my scripts can be found here.
Out of the ~5,900 reachable nodes on IPV4, my attempt to download 10 blocks went as follows:
Pruned nodes: 698 (thus older blocks are not available)
Block Download Failed: 2,179
Block Download Succeeded: 3,028
Of the 3,000 successful block downloads, the download speed were distributed as follows. Note that the x axis on the next 2 charts is linear except for the final bucket which contains the 1% outliers - otherwise the charts would be very hard to read because they would mostly be empty space.
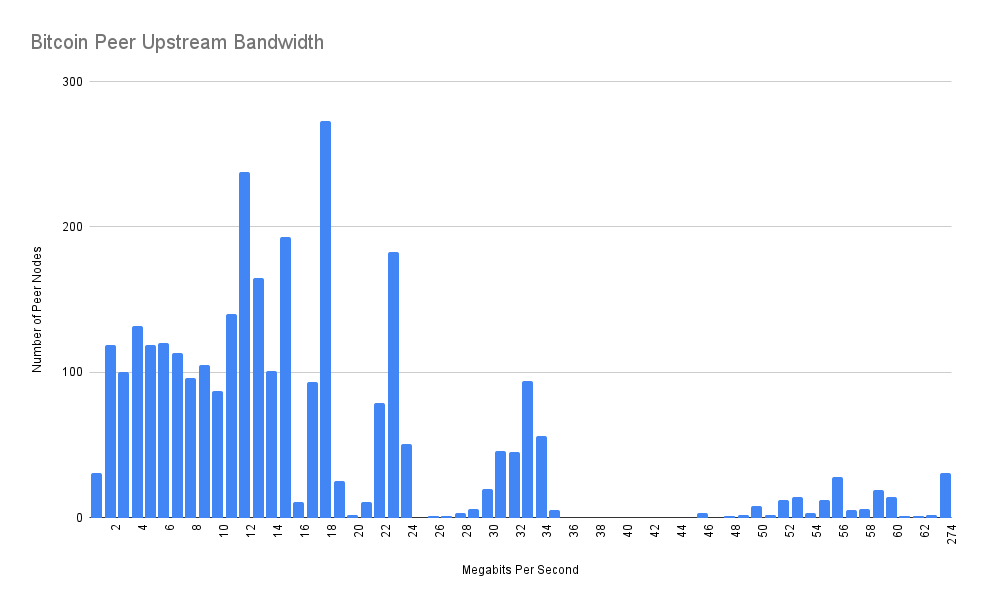
Average Peer Speed: 17.3 megabits per second
Median Peer Speed: 12.1 megabits per second
So... this is not great! But how accurate was my crawler script? I'm certainly not confident enough in it to submit these results to a peer reviewed journal. I only ran the crawler one time because it took several days to complete, and the bitcoin p2p message logic I wrote was really hacky so I'm sure it has some bugs.
It turns out that Bitnodes also tracks peer node bandwidth, so I wrote another script to collect the data from each node's individual metrics. The results are an order of magnitude worse! Of the 5,350 IPV4 nodes for which I was able to get bandwidth metrics from Bitnodes, the speeds are distributed as follows.
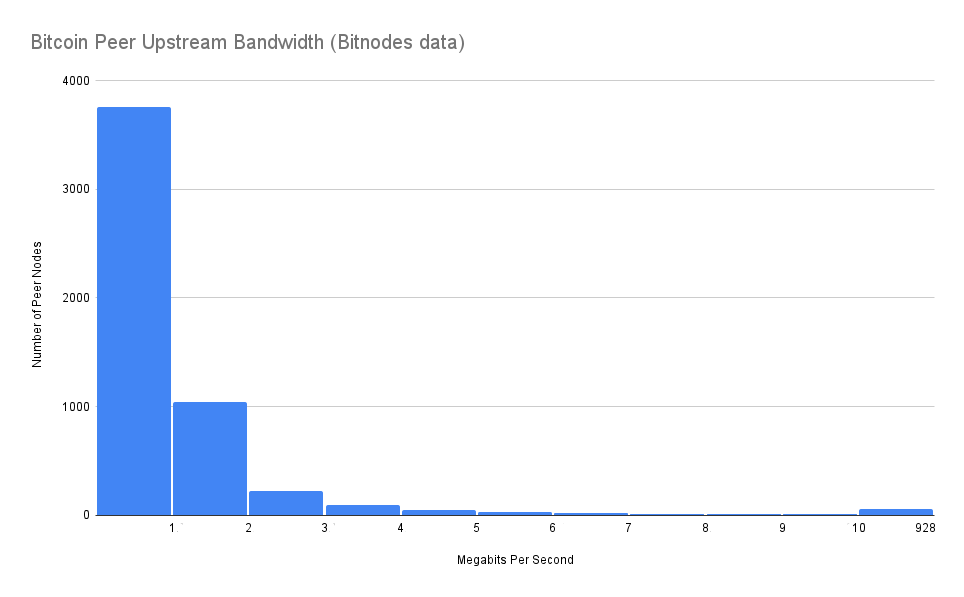
Average Peer Speed: 2.0 megabits per second
Median Peer Speed: 0.8 megabits per second
It's clear that the methods used by my script and by Bitnodes are significantly different. My script's stats are skewed higher because I only gave a peer 2 minutes to respond to a request before disconnecting. As such, since my script was requesting 78 megabits of block data, if a peer's available upstream bandwidth was less than 0.64 megabits per second my script would time out, disconnect, and throw out that result. This lines up with the total number of peers in the two different data sets; my script only returned 3,000 peers while Bitnodes has 5,350 because my script threw out the results for the ~35% of peers that have less than 0.64 megabits per second of upstream.
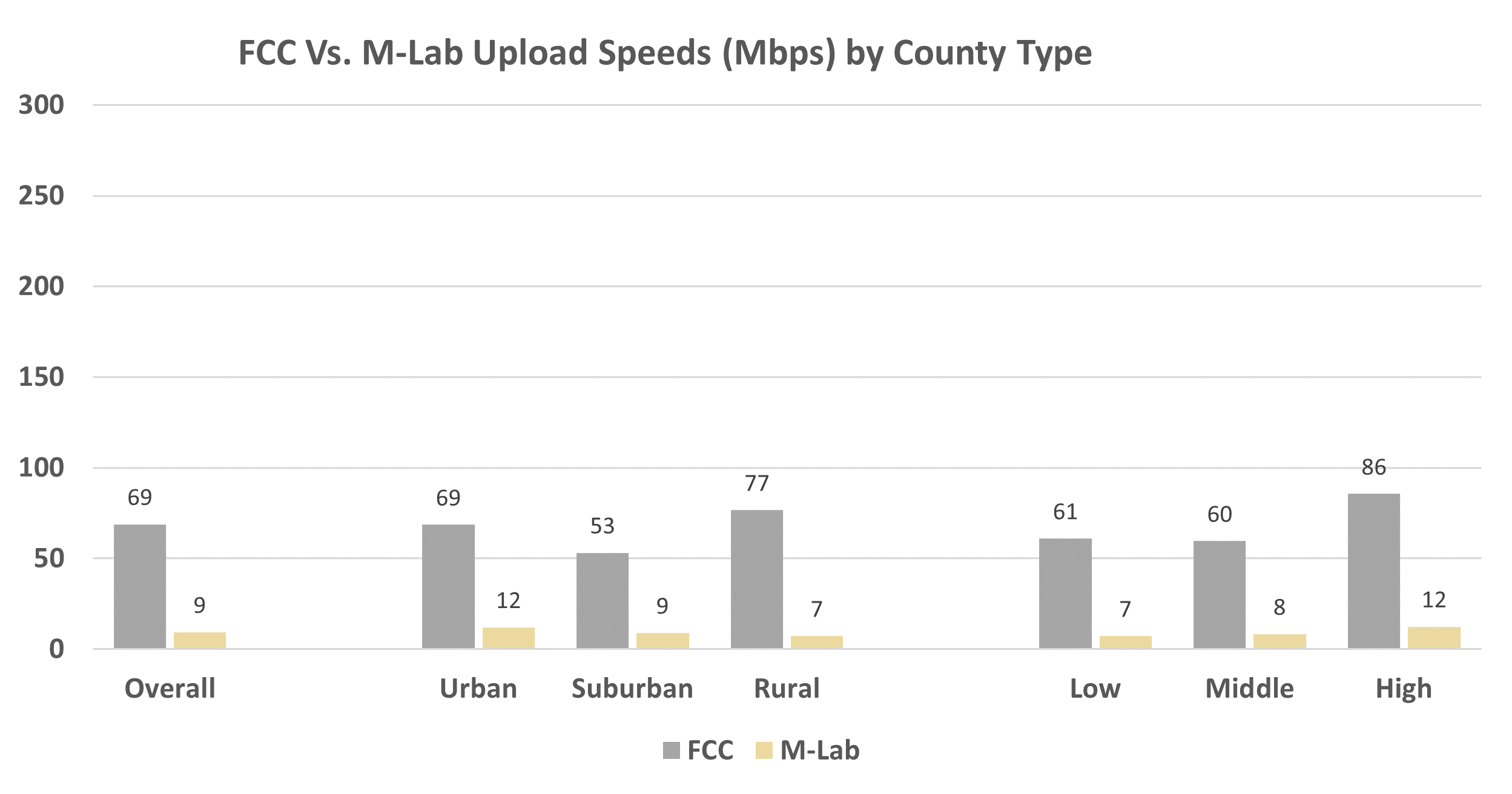
My initial guess for this explanation is that it's due to the asymmetric nature of residential ISP connections - your upstream tends to be an order of magnitude smaller than your downstream. It turns out it's pretty hard to find data on real-world upstream bandwidth, but this report released by Purdue in 2020 seems to confirm what I'm seeing, at least for America. While the FCC and ISPs will claim that upload speeds average ~70 Mbps, the real-world performance is an abysmal 9 Mbps. If we consider that the average residential node runner's connection will likely have dozens of peers and they'll be doing other things with their internet, it's not surprising that only half a megabit of upstream would be made available to a random peer node that requests blocks.
Final Thoughts
Is this an existential threat to the network? I don't think so, it's just a minor annoyance for folks like myself who are seeking maximum initial block download performance. It's tricky to complain about this issue because what we're really talking about is a publicly available resource that is being offered for free from a group of volunteers.
This is, however, something that Bitcoin node implementations should think about with regard to their "stalled peer" logic. Take Bitcoin Core, for example:
bitcoinAs noted earlier, if Bitcoin Core determines that your (1,000 block) moving window of blocks being downloaded is not progressing forward for 2 seconds then it will disconnect from the peer that's being the blocker and assign its blocks to a new peer. However, that new peer will only have 2 seconds to return the first requested block. A full block is over 8 megabits of data which means the peer needs to send it faster than 4 megabits per second. But according to Bitnodes' peer bandwidth stats, 96% of reachable IPV4 peers are slower than 4 megabits per second! So it's easy to see how your node could get stuck in a "stalled peer" loop for a minute while it desperately cycles through peers trying to find one that's faster than 4 Mbps. And then depending upon the speeds of the other peers from which your node is syncing, this process could repeat itself many times throughout the initial block download, causing significant aggregate delays.
In short, I think that any stall logic that uses hard coded timeouts is going to be suboptimal. Rather, a node should keep track of the actual bandwidth speeds it's seeing from each peer and if one peer is being a bottleneck, it should switch to requesting the data from a peer that it knows will serve it quickly rather than randomly switching to a new peer and hoping it will be fast enough.
Unfortunately, despite all of this analysis I still haven't really answered the question posed at the beginning of this article, because we simply don't have historical network-wide node bandwidth statistics available. This may be worth revisiting in the future to see if there's a clear trend.




