Revisiting Bitcoin Network Bandwidth Issues

Five years ago I started running annual full validation sync performance tests of every Bitcoin node I could find. It was interesting to watch over the years as well-maintained node software got faster while less maintained node software fell behind. But something weird happened during my 2021 testing - I observed unexplained slowdowns across the board that appeared to be network bottlenecks rather than CPU or disk I/O bottlenecks. These slowdowns disappeared when I re-ran my syncs while only requesting data from peer nodes on my local network.
In 2022 I dove a bit deeper into this issue with the following report:

Recently I saw this code change get merged into Bitcoin Core and summarily released in v25.0:
 bitcoin
bitcoinDuring initial block download, there is a stalling mechanism that triggers if the node can't proceed with assigning more blocks to be downloaded in the 1024 block look-ahead window because all of those blocks are either already being downloaded: we'll mark the peer from which we expect the current block that would allow us to advance our tip (and thereby move the 1024 window ahead) as a possible staller. We then give this peer 2 more seconds to deliver a block (BLOCK_STALLING_TIMEOUT) and if it doesn't, disconnect it and assign the critical block we need to another peer.
The problem is that this second peer is immediately marked as a potential staller using the same mechanism and given 2 seconds as well - if our own connection is so slow that it simply takes us more than 2 seconds to download this block, that peer will also be disconnected (and so on...), leading to repeated disconnections and no progress in downloading the blockchain.
As of Bitcoin Core v25 the timeout is adaptive: if we disconnect a peer for stalling, we now double the timeout for the next peer (up to a maximum of 64 seconds.) If we connect a block, we halve it again up to the old value of 2 seconds. That way, peers that are comparatively slower will still get disconnected, but long phases of disconnecting all peers shouldn't happen any more.
Verifying the Fix
I decided to run a variety of different test syncs to determine what effect, if any, this change has in the real world.
- v24 default validation sync against public peers
- v24 full validation sync against public peers
- v25 default validation sync against public peers
- v25 full validation sync against public peers
- v24 default validation sync against a local network peer
- v24 full validation sync against a local network peer
- v25 default validation sync against a local network peer
- v25 full validation sync against a local network peer
All the test syncs shared the following config values in common; the only difference was whether I set "assumevalid=0" to force signature validation for all historical transactions while for local network syncs I set "connect=<local_peer_ip>"
dbcache=24000
disablewallet=1On to the results!
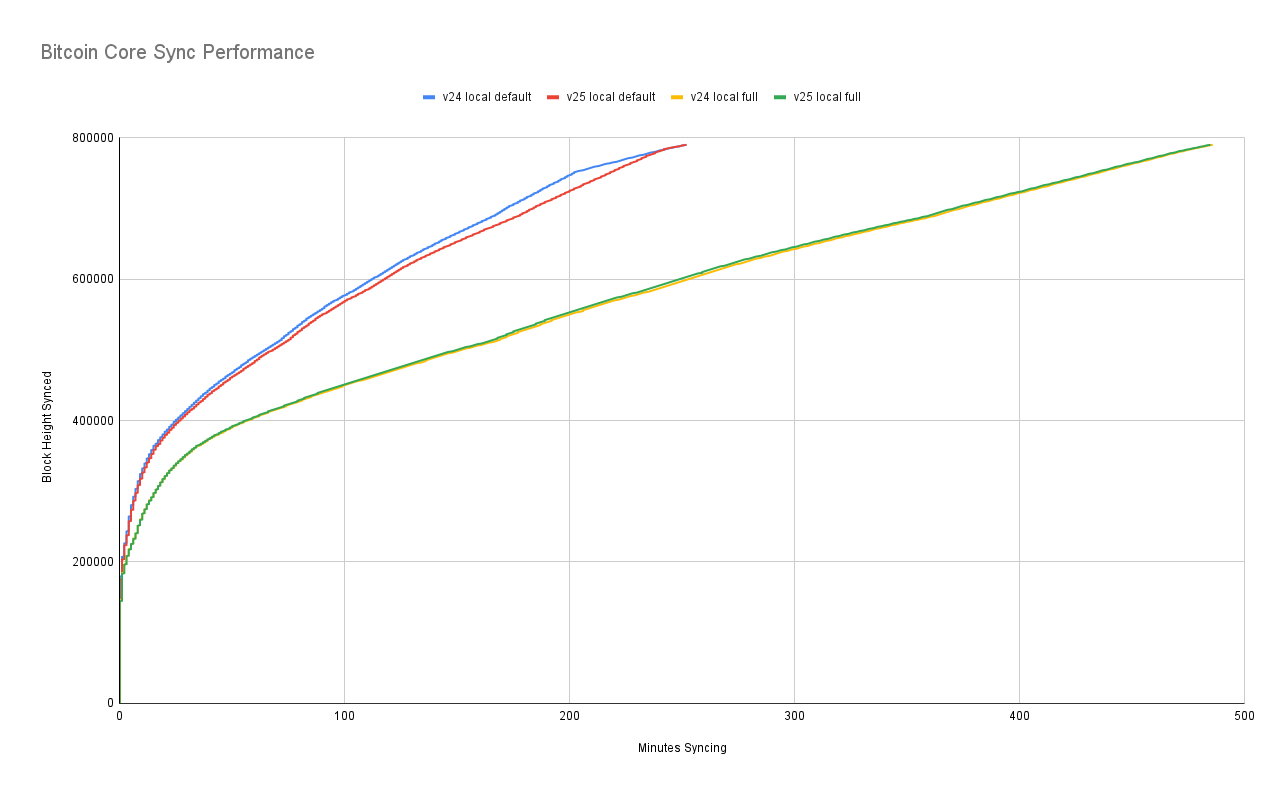
Here we can clearly see the different between doing a default validation versus doing a full validation of all historical signatures. Oddly enough, it looks like the default v25 validation is slightly slower. Though note that all of these tests were done against a local network peer, so the stalling change would have no effect upon performance. You may also notice that the v24 validation slows down a lot after 200 minutes - this is because it hits that point at which it starts validating historical signatures.
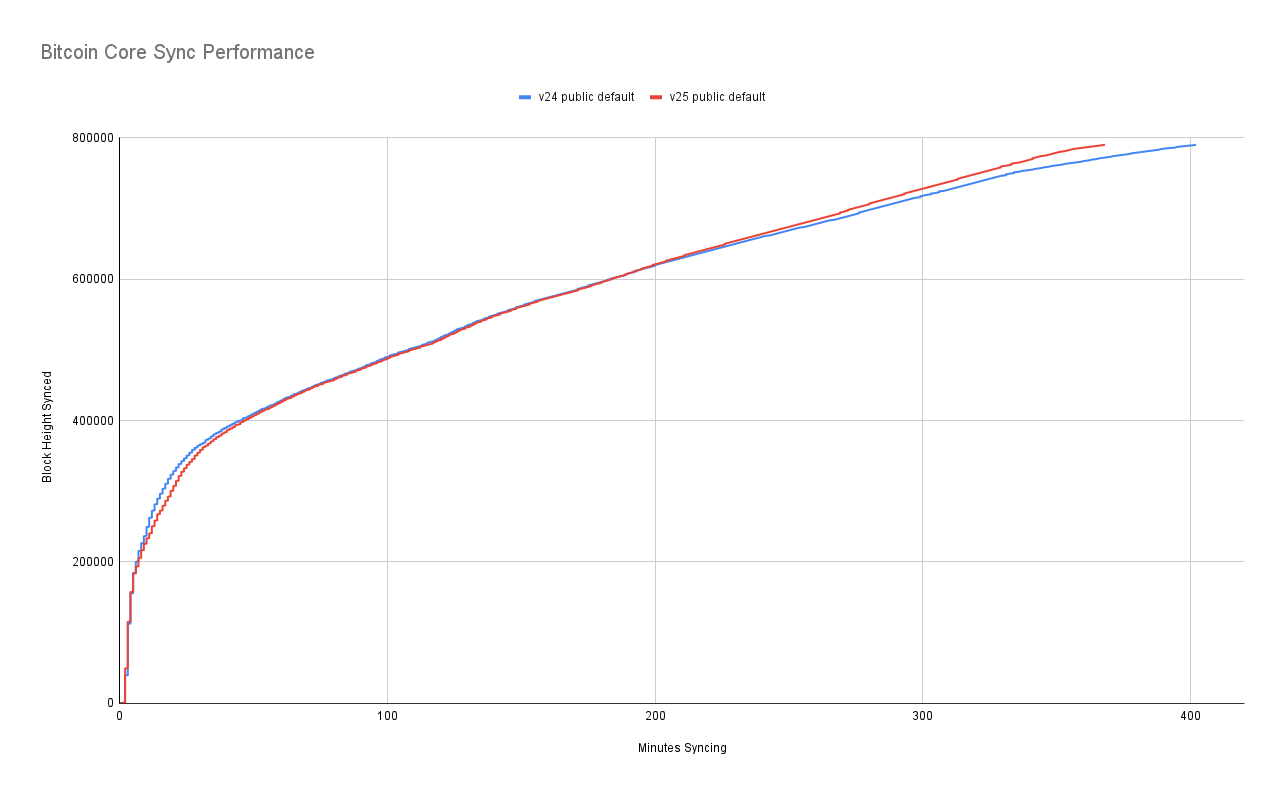
What if we compare v24 to v25 against public peers? v24 is slightly faster at syncing early blocks, but otherwise it's a dead heat. Once again, the divergence at the end is attributed to the difference between when each client starts to validate historical signatures and becomes CPU-bound. To get rid of that variable we need to do full validation syncs.
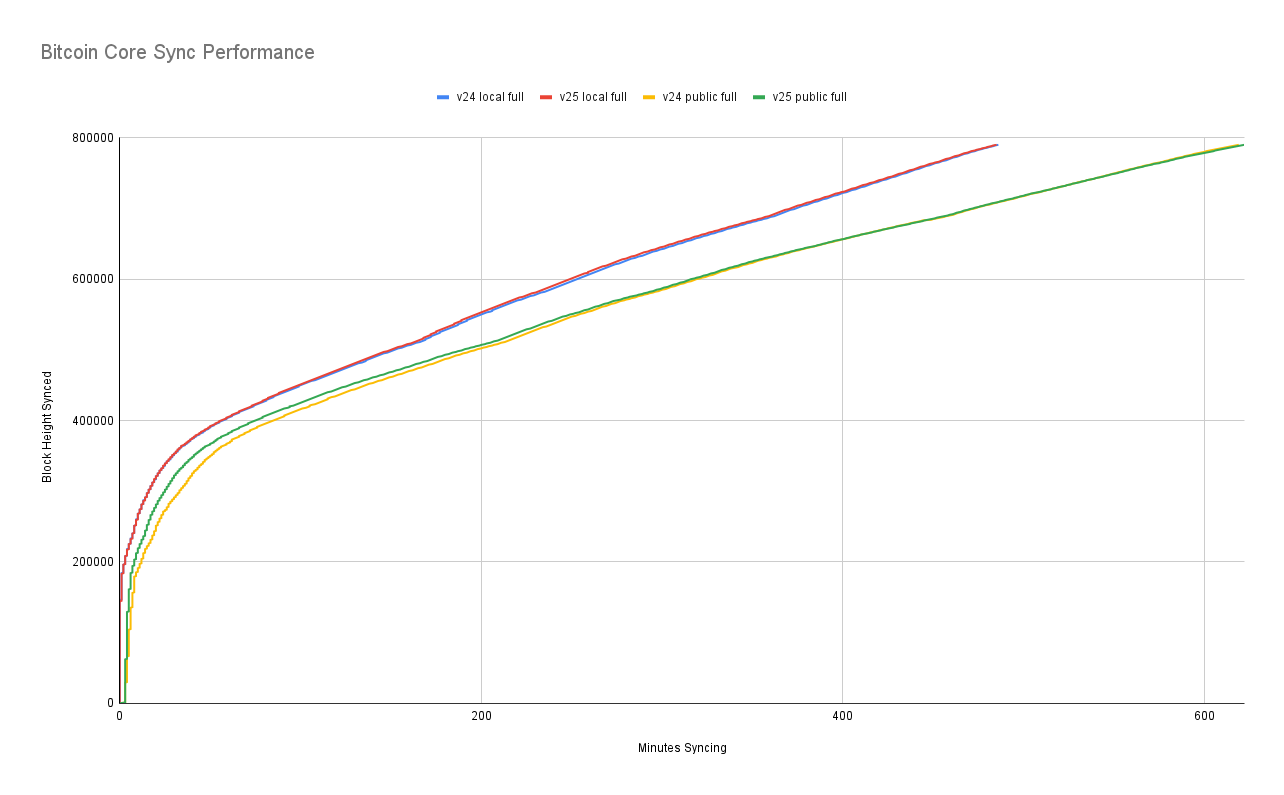
With full validation syncs we can observe essentially no difference between the two releases when syncing against a local network peer, as expected. Against public peers, we can see that v25 is slightly faster for the first 4 hours but then they converge. For reference, I was expecting the performance chart to look more like this one from last year's tests:
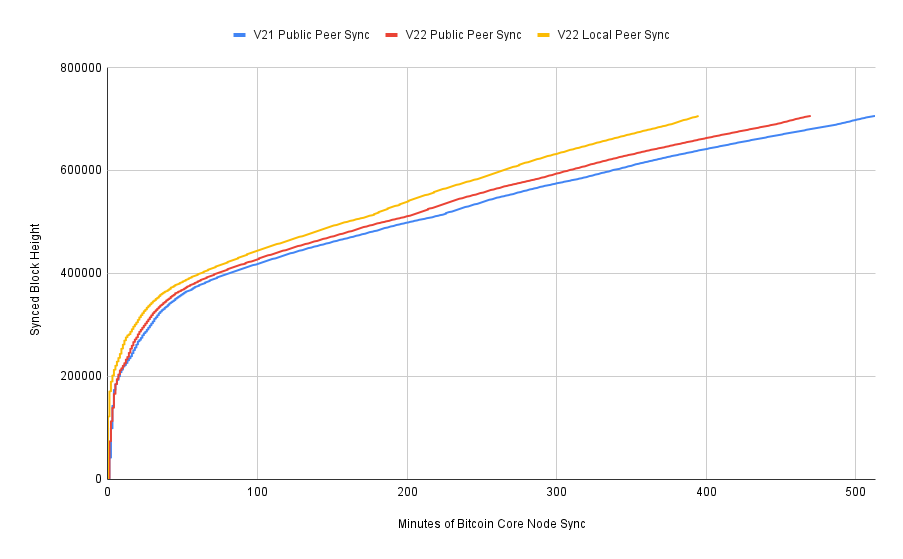
I struggle to explain the convergence, but will also note that I only ran one test sync for each of the 8 node configurations due to the time requirements. Given more resources it would be preferable to run 10+ syncs of each from a variety of different geographic locations.
The Landscape of Publicly Reachable Node Bandwidth
Has the overall network health changed significantly since last year? I re-ran my network crawler script to measure each publicly reachable peer's bandwidth.
Total IPV4 nodes: 5,467
Pruned Nodes: 831 (can't be used for full chain sync)
Failed to return requested blocks: 2,153
Successfully returned requested blocks: 2,483
Of the 2,483 nodes for which I was able to measure their bandwidth, the breakdown was as follows:
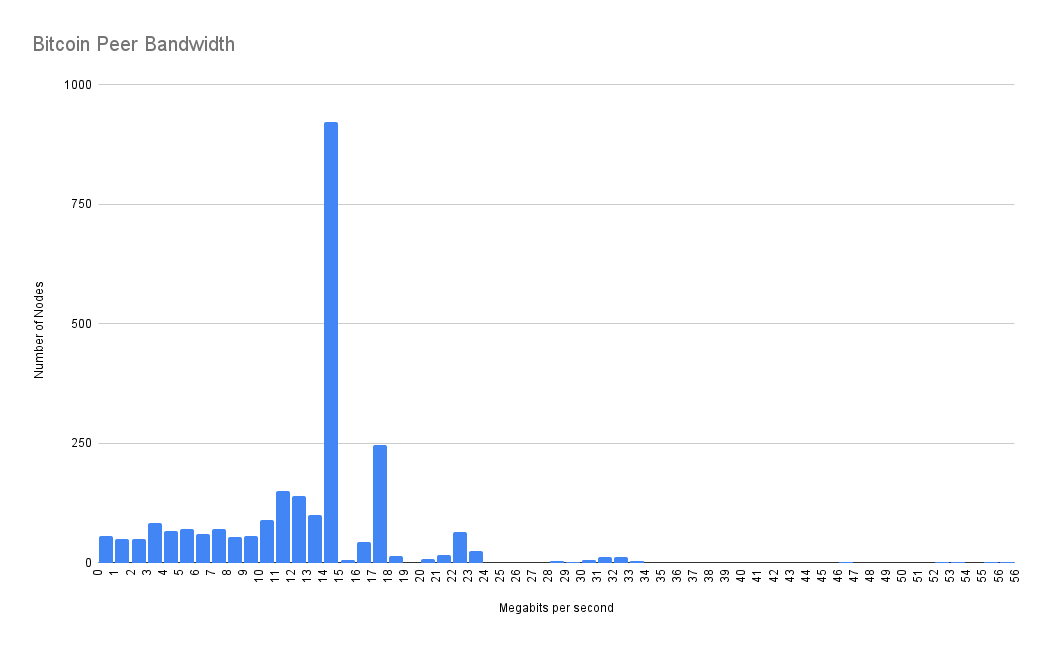
Average peer upstream: 12.8 Mbps
Median peer upstream: 14.3 Mbps
These figures are similar to last year's results of 17 Mbps and 12 Mbps, though the distribution is quite different. Last year's test found more peers in the 30 Mbps range which brought the average higher. One possible explanation for why so many peers are in the 14 - 15 Mbps range: looking at Comcast and Spectrum's subscription plans, their highest non-gigabit tiers tend to cap the upstream at 15 - 20 Mbps.
Further Experimentation
There are a ton of variables at play when doing an initial sync of your node against publicly reachable peers.
- Bitcoin Core only opens 10 outbound connections
- It selects those connections randomly from lists of IP addresses it receives from DNS seeds. It queries all 9 DNS seeds and, in my testing, each seed returns about 40 IP addresses. About 2/3 are IPV4 and 1/3 are IPV6. Thus if you're an IPV4 node you'll have about 250 peers to try and if you're IPV6 only 120 peers to try.
- Bitcoin Core only maintains a download window for the next 1024 blocks
What if Bitcoin Core connected to more peers? We can test that by recompiling Core with a single line of code changed:
diff --git a/src/net.h b/src/net.h
index 9b939aea5c..41b182ac53 100644
--- a/src/net.h
+++ b/src/net.h
/** Maximum number of automatic outgoing nodes over which we'll relay everything (blocks, tx, addrs, etc) */
-static const int MAX_OUTBOUND_FULL_RELAY_CONNECTIONS = 8;
+static const int MAX_OUTBOUND_FULL_RELAY_CONNECTIONS = 48;
What if the download window was larger? As noted in the code, this would cause more fragmentation on disk which slows down rescans, but those are rare operations. Once again, we just need to change one variable:
diff --git a/src/net_processing.cpp b/src/net_processing.cpp
index b55c593934..663689de29 100644
--- a/src/net_processing.cpp
+++ b/src/net_processing.cpp
@@ -127,7 +127,7 @@ static const int MAX_BLOCKTXN_DEPTH = 10;
* Larger windows tolerate larger download speed differences between peer, but increase the potential
* degree of disordering of blocks on disk (which make reindexing and pruning harder). We'll probably
* want to make this a per-peer adaptive value at some point. */
-static const unsigned int BLOCK_DOWNLOAD_WINDOW = 1024;
+static const unsigned int BLOCK_DOWNLOAD_WINDOW = 10000;
I next ran another set of syncing tests to compare tweaking the above variables.
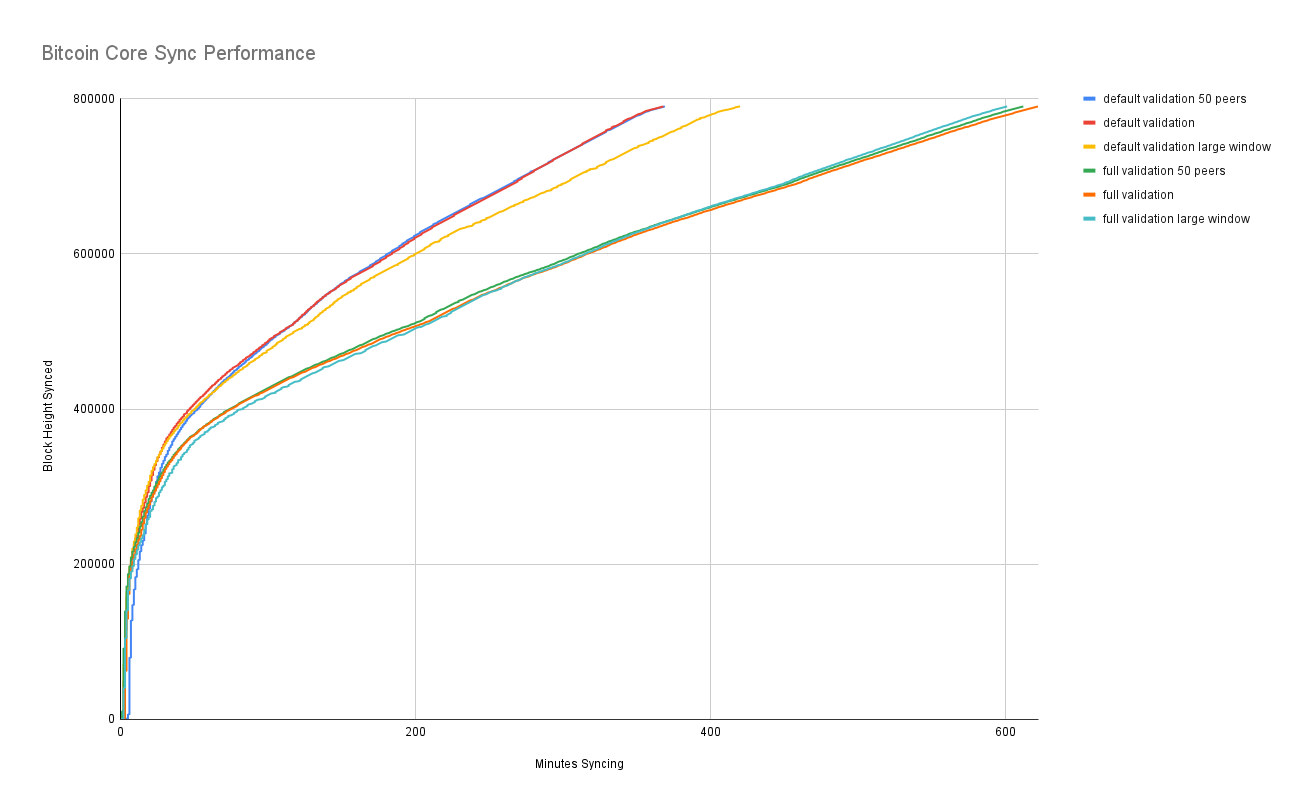
What are the takeaways? Increasing the download window size actually seems to harm download performance. Adding more peers seems to have a negligible effect. While there's probably room for improvement somewhere in the peer management logic, neither of these options appears to do the trick.
It might be worth improving Bitcoin Core's peer management to keep track of the actual bandwidth speeds it's seeing from each peer and drop slow peers that create bottlenecks, though this would require a fair amount of adversarial thinking to ensure that such a change doesn't create a potential eclipse attack by high bandwidth / enterprise / data center nodes.
Conclusion
While the performance gains I observed were muted in comparison to my expectations, there are a lot of uncontrollable and even unknown variables at play. For example, we'll probably never know if there were maliciously slow peers running on the network last year that may be gone now.
What should the average Bitcoin enthusiast take away from all of this? If you have a high speed residential connection that doesn't have a pitifully throttled upstream, please consider running a node that accepts incoming connections!




