Bitcoin Testnet Block Storms

Ripple Effects from a Consensus Rule Tweak
From time to time I'll see someone publicly post a question along the lines of "WTF is going on with testnet right now?" I've been observing wacky testnet activity since I started working on running Bitcoin infrastructure full time in 2015.
The recent third testnet block storm in as many weeks set a new record of 12,682 blocks mined in a single day. pic.twitter.com/PpV4C1C8HP
— Jameson Lopp (@lopp) May 5, 2015
I could be wrong, but logs suggest one of my testnet nodes hit a 2,000+ block orphan chain during last block storm. pic.twitter.com/9QV8ymIDav
— Jameson Lopp (@lopp) May 28, 2015
In some cases people notice that testnet APIs and block explorers get stuck with their last block found hours ago or may report an unusually high number of blocks found with a very high orphan rate. The root cause is almost always the same: abnormal network activity due to one of testnet's unique attributes.
Background: Mining Difficulty Retargeting
Bitcoin miners create blocks by solving (via brute force) the proof of work for their proposed block. The difficulty for the entire network of miners to solve a block is regularly adjusted in order to target a block interval averaging 10 minutes, but not every block interval is exactly 10 minutes. It follows a statistical process known as a poisson process, where random events happen with the same probability in each time interval. The result is that about 10% of the time (once every couple hours) you'll have to wait over 20 minutes for the next block while about 0.3% of the time (once every few days) you'll have to wait over an hour for a block. This isn't great for developers who need their transactions confirmed in a timely manner while testing!
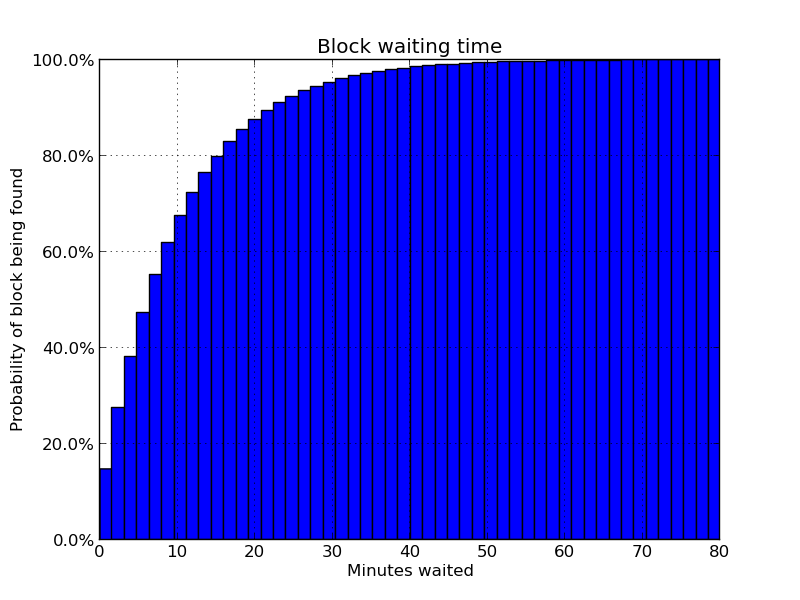
To make testing a bit more predictable we need to have blocks mined more consistently. We already know that hashing power on the testnet will be less predictable because there is no economic incentive to mine on testnet - TBTC coins have no monetary value. As such, miners will come and go as people are testing new mining hardware and software.
Due to the unpredictability of hashing power and block times there’s a special rule that allows a block to be mined against the minimum difficulty of 1 (and thus practically instantly on a GPU or ASIC) if there hasn’t been a block for 20 minutes. This rule gets invoked fairly regularly on testnet. In fact, I wrote this script to determine just how often. It turns out that nearly 200,000 blocks (nearly 12% of all blocks) on testnet have been mined at a difficulty of 1 after the 20 minute window has passed since the previous block.
It is worth noting that due to some leeway allowed around block timestamps it's possible for an adversarial miner to set their timestamp 20 minutes into the future and mine a block at a difficulty of 1, but they'd only be able to do this at most 6 times before hitting the "2 hours in the future" rule. I discussed block timestamp security in depth in this post.
Testnet's Unique Rule
At time of writing, the logic for calculating the difficulty (proof of work required) for the next valid block can be found here in pow.cpp. We see that testnet has a special flag, fPowAllowMinDifficultyBlocks, set to true, which changes the logic that gets executed when calculating the next block's difficulty.
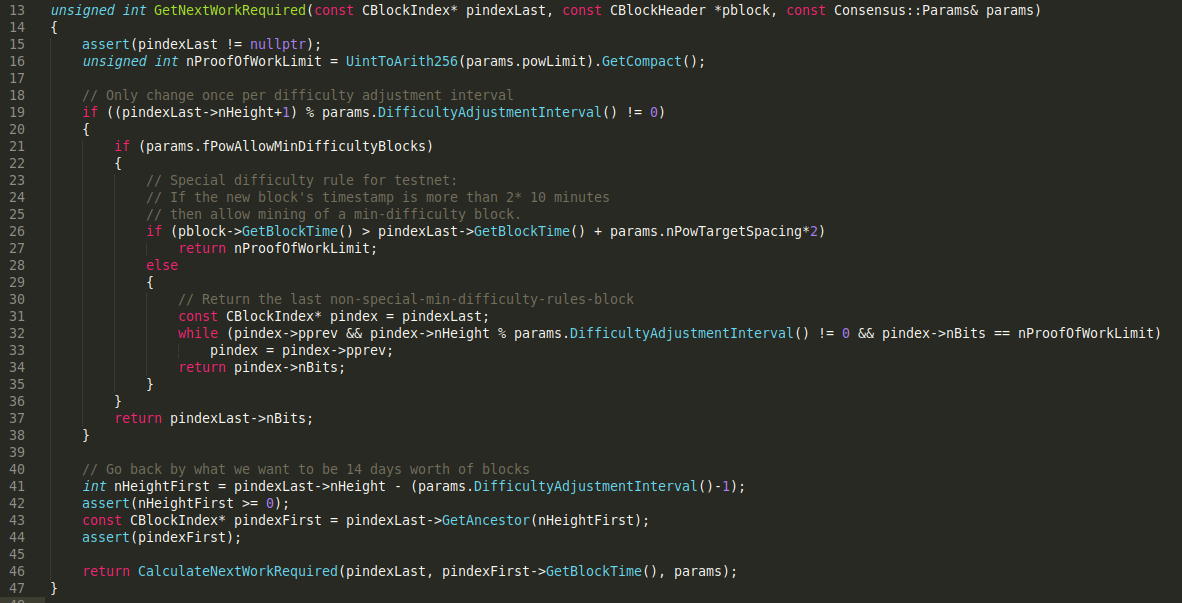
If we trace back the changes to this block of code we see that it was originally written by Gavin Andresen in late 2011:
 bitcoin
bitcoin
We see that several contributors gave feedback on this change and mentioned issues that needed to be fixed. Notably, Matt Corallo questioned the particular placement of this new logic:
Why inside the interval check? If we are on the cusp of an interval, why shouldn't we allow min-diff blocks?
While it seems that Matt was onto something, it appears that none of the 5 developers who participated in this pull request noticed a substantial edge case created by this code. It's completely understandable because I had to read through the logic several times myself while already knowing the side effect before it was clear how it was happening.
Unanticipated Interactions
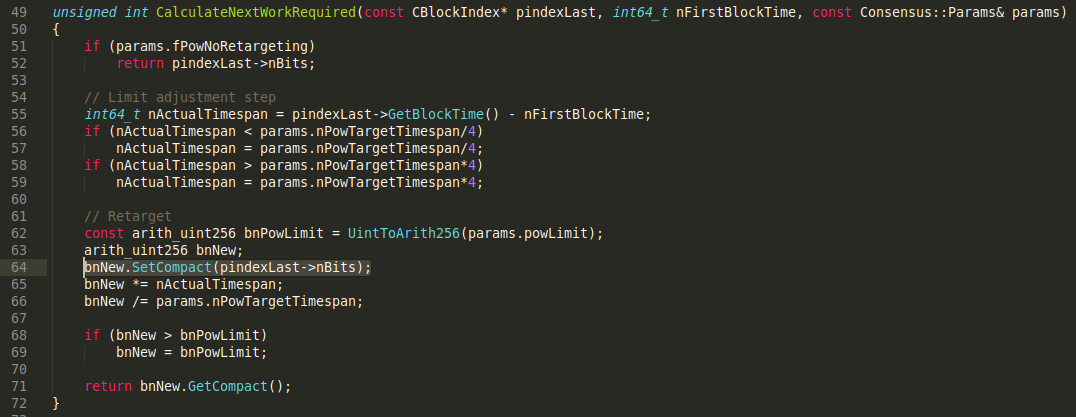
Just like the normal bitcoin network, testnet also recalculates the mining difficulty every 2016 blocks. However, the logic for calculating the new difficulty was written with the assumption that previous blocks were all validated against the same difficulty target calculation and thus it's safe to continue this series of difficulty calculations. This is similar implicit logic to how Bitcoin's 21 million BTC limit is assured - a node never actually sums up all of the UTXO values but rather assumes that every previous block has been validated not to create more than the allowed subsidy, thus the sum must implicitly be below the total limit.
Thus, on testnet when the block before the retarget (block #2015, #4031, etc) is a difficulty 1 block due to the special minimum difficulty rule, the retarget logic for the next block will run based upon the assumption that the difficulty for the entire previous 2015 blocks has been 1! And because a retarget is bounded to never increase the "current difficulty" by more than 4X, the new difficulty will be recalculated to be either 1, 2, 3, or 4.
At time of writing testnet has 1,694,700 blocks which means there have been 840 difficulty retargets. We can see that 99 of those difficulty retargets have resulted in the difficulty being "permanently" reset to 1. This is exactly how many retargets we'd expect since it's also 12% of all retargets, thus matching the rate at which the special testnet difficulty rule gets triggered. So while theoretically an adversarial testnet miner could have easily waited for the block height to reach 1 block before a difficulty recalculation and then mined a difficulty 1 block with a timestamp 20 min in the future in order to trigger a difficulty reset, it doesn't appear that this has been happening.
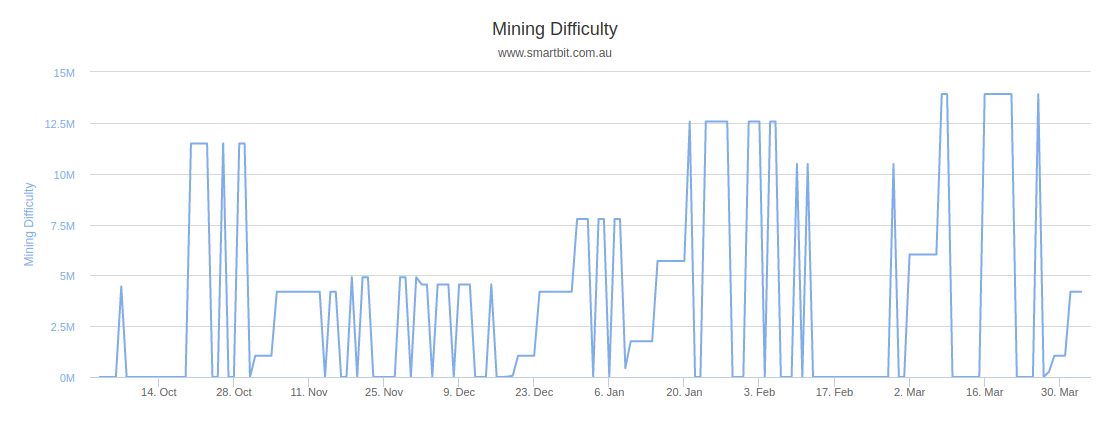
We can see that this creates extreme volatility swings in the difficulty on testnet, causing it to move by as much as 7 orders of magnitude in either direction.
Breaking Block Explorers & Other Services
Why does the difficulty reset cause such strife with services running on testnet? It's because once the difficulty gets reset to 1, even a cheap ASIC like an S5 can mine multiple blocks per second. As you might imagine, if you then have dozens of testnet miners spewing blocks onto the network, there will be quite a few conflicts.
When a Bitcoin node receives a new conflicting set of blocks that have more proof of work than what it considers to be the current best chain, it has to perform a blockchain reorganization. This involves sequentially rolling back the current chain of blocks and transactions and then applying the new chain - it's a highly intensive process that happens very rarely on the main network, and almost never with more than one block at a time. Many naively written nodes or services will simply perform this operation in memory as a performance improvement, but when they're served with a reorganization that has hundreds or thousands of blocks the machine may run out of memory and cause the node or service to crash, thus freezing it at the last successfully processed block. It's also possible that the service may not have a lock around this operation and if it's in the middle of performing a reorganization while another reorganization comes along, the service will freeze / deadlock / corrupt data.
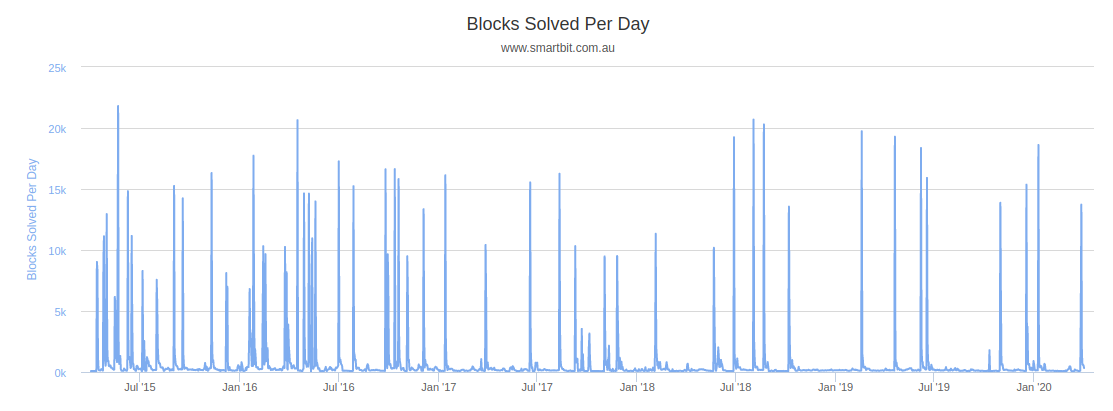
We can see that while during a normal day around 144 blocks are minted, if a difficulty reset to the minimum difficulty occurs, it results in over 10,000 blocks being mined! That's a block every 8 seconds!
Fixing the Problem
While it would be trivial to patch the logic so that it doesn't trigger permanent difficulty resets to the minimum difficulty, this is consensus critical code. Such a change would require a hard fork of the network., though this is testnet so it's not as huge of a deal as mainnet. It would still be a pain for many companies and developers to have to coordinate an update.
However, it would be a wasted effort because an improved testnet has been under development for some time. Karl-Johan Alm is working on BIP 325 to add functionality for developers to run "signet" test networks that don't use mining at all, but rather use a federation of block signers. You can read more about Signet at Bitcoin Magazine.
Takeaways
It's hard to see edge cases, especially around logic that is implicit rather than explicit. Such logic adds to the difficulty of reviewing code safety because the reviewer has to keep all of the assumptions made by other parts of the codebase in mind while reviewing the changed code.
It's also hard to predict the future and thus write future-proof code. At the time this code change was made, the difficulty of the main Bitcoin network was only 1 million and ASICs hadn't even been invented. At time of writing mainnet difficulty is over 15 trillion and even testnet's difficulty often exceeds 13 million. Insane difficulty fluctuations probably didn't even cross the minds of developers at this time.
Thankfully this particular bug only affects testnet, which has no monetary value, but it does cause "damage" in the sense that developers such as myself then have to spend time repairing infrastructure. It goes to show how careful and conservative protocol developers must be when modifying consensus critical code. This is mission critical code that can have far-reaching ramifications and it should be approached from a mindset akin to aerospace engineering due to the potentially catastrophic consequences of even a "minor" flaw.





