The Challenges of Blockchain Indexing

Over the past several months I’ve had the pleasure of enhancing BitGo’s block chain indexing service — a core component of our infrastructure. If you run a block chain based service that needs to track address balances or quickly access arbitrary data, customized indexing software is a must. I’ve come to learn that while processing a static block chain is a straightforward task, doing so in a manner that scales better than O(n) as the block chain grows poses additional challenges. And once you have mastered processing a static block chain, processing a dynamic block chain in realtime poses even greater challenges.
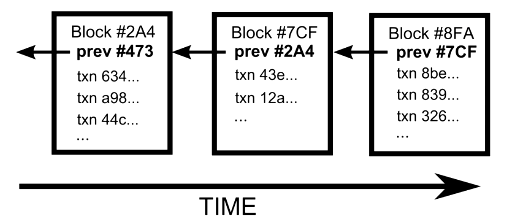
Due to the ordered nature of data in block chains, they must be processed in order from genesis to chain tip if you want to ensure the integrity of your data. The naïve way to do so is to request the genesis block from a node and then iterate through each transaction in the block, indexing the values you need for your application. Once you index the last transaction in the current block, you then request the next block and repeat the process until you find yourself at the tip of the block chain. This certainly works, but it scales linearly — as the block chain grows the time to index the entire chain will grow at the same pace as the total number of transactions. At time of writing, using this approach on the Bitcoin block chain’s 70,000,000 transactions with a powerful desktop can take days to complete.

Unfortunately, block chain indexing is a difficult problem to parallelize due to the dependencies between transaction inputs and outputs in different blocks and even between transactions in a single block. It is possible to parallelize the processing of transactions, but you’ll quickly find that individual transaction indexer workers get stuck trying to process a transaction that spends outputs from a parent transaction that has not yet been processed. It’s also possible to further parallelize processing by allowing transaction indexing workers to jump forward to transactions in future blocks, essentially continuing until they hit an unmet dependency. I don’t recommend this, however, because if your indexer gets stuck then you’ll have a more difficult time figuring out exactly where in the block chain you need to resume indexing once you resolve the problem.
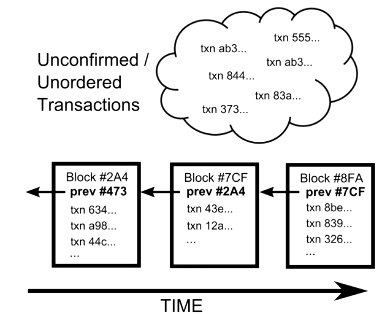
While the biggest challenge to indexing a fixed block chain is doing so quickly, indexing blocks and transactions in realtime as they are broadcast over the network is a completely different problem set. Instead of only dealing with a neatly ordered set of transactions in blocks, you have to deal with a hot mess of events that threaten to break your output chains. Some of these problems include:
- Reorganizations
- Double spends
- Spending of unconfirmed unspent outputs
- Chaining of multiple unconfirmed outputs
- Transactions that never get confirmed
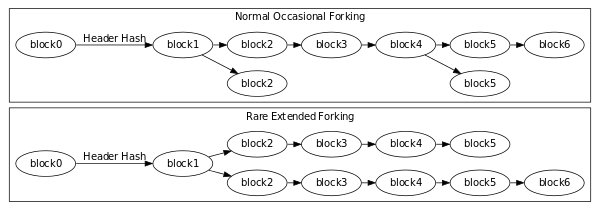
Reorganizations are a major event on the block chain; when one arrives you must stop what you’re doing, roll back all the transactions (preferably in reverse order of their positions on now-orphaned block chain,) and then process the transactions on the new best chain. While you’ll only see about one reorganization per day on mainnet, I’ve seen as many as one per second during block storms on testnet. During such block storms I have even observed reorganizations occur on testnet that orphan chains over 100 blocks long. When these block storms first appeared, they broke over half of the public testnet block explorers because they were not robust enough to handle the unexpected volume of events.
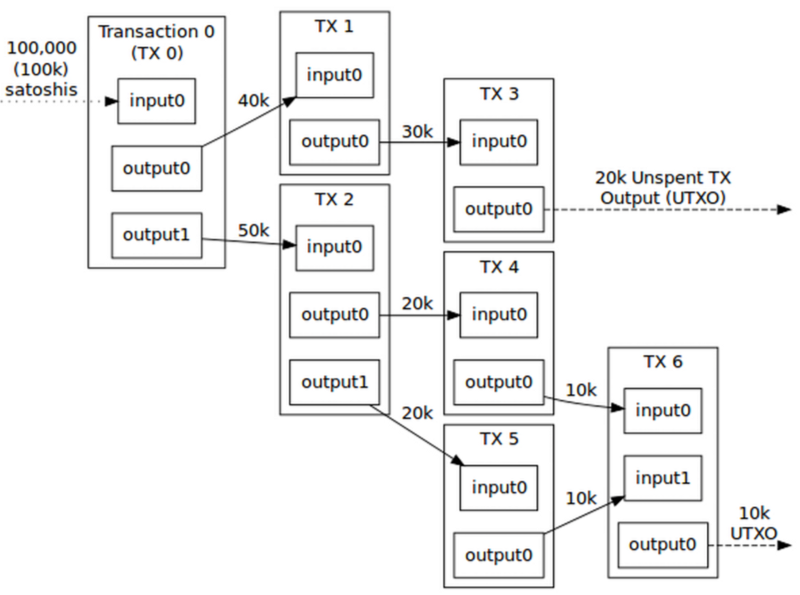
Double spends can be easily guarded against by checking that the transaction is only spending unspent outputs; if an unconfirmed transaction tries to spend an output that is already spent, just throw it away. However, if a confirmed transaction tries to spend an already-spent output, you know that the first unconfirmed transaction you processed was the double spend. In this situation the first transaction must be reverted before indexing the confirmed transaction. Similar logic applies to transactions that spend unconfirmed UTXOs, potentially even chaining many such transactions together. Just as a block chain reorganization can invalidate a slew of blocks, a long chain of unconfirmed transactions spending each others outputs can be similarly invalidated if a confirmed transaction arrives that proves the unconfirmed transaction chain to be descendants of a double spend.
Lastly, because some transactions never get confirmed, you should periodically check for unconfirmed transactions that have been pending for several days and revert them. If these transactions end up being confirmed in the future then they will arrive in a block and get reprocessed.
The interconnectedness of block chain data requires that your indexer be bulletproof and never silently fail. Think of the UTXO set as an unending series of fan-out (and sometimes fan-in) operations; if you miss a single update then the resulting series of errors can cascade such that your index is eventually corrupted to the point of unusability.
As a result it’s crucial to use a reliable data store and highly recommended to use one that supports transactions. Otherwise, if a single write goes wrong you’ll need to have logic in your code to handle rolling back the other related writes so that you don’t end up with a corrupt index.
In order to prove the robustness of our indexing service, I used some of the tools from Bitcoin Core’s test suite to build a network simulator that spools up several nodes locally in regtest mode and generates random transactions, blocks, blockchain forks, and problematic behavior. This has proved an invaluable QA mechanism and also accelerated the rate at which I can fix edge case bugs since I can reproduce rare events locally without having to wait for them to occur on testnet.
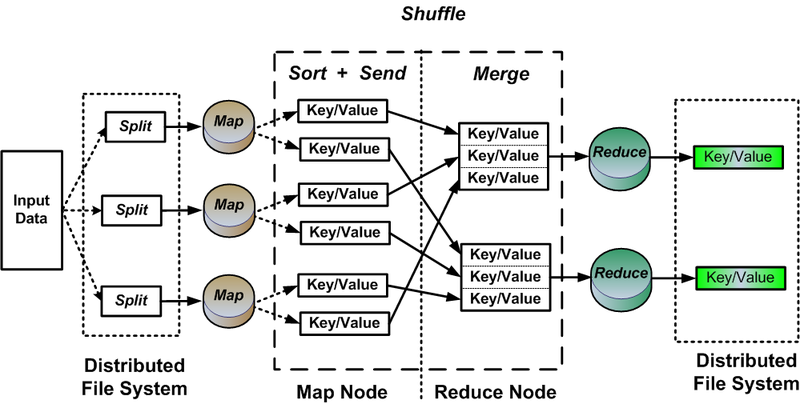
While I’m pleased with the current state of our indexing service, it’s clear that more scalability issues loom on the horizon, should Bitcoin continue to increase in popularity. I hope to eventually investigate the feasibility of truly parallelizing static block chain indexing by loading pre-validated block chain files from Bitcoin Core into HDFS and processing them with a MapReduce cluster. This would allow you to skip the tedious work of checking input dependencies and managing the order in which the transactions are processed. After the MapReduce job completes, you can then fire up your realtime indexing service to keep the block chain up-to-date. I can envision an initial MapReduce phase that adds up all of the outputs to compute the ‘total received’ balances of every address, then a second phase that subtracts all of the spent output values, eventually arriving at the current address balances. With a sufficiently sized cluster you should be able to reduce the initial index build time from several days to a matter of minutes.
We’re still in the early days of block chain technology and scalability is only now beginning to become a concern at the protocol level. I look forward to continuing to apply my skills toward managing scalability at the higher levels of the block chain technology stack!




