Open Source Transcription Software Comparisons

I was amazed by the advancements in AI that started taking off in 2022, from image generation to text generation to audio interpretation. I delved into OpenAI's transcription technology because transcribing (and translating) my mountain of content has been a project I've thought about in passing several times over the years, but always seems like it would require me hiring out a service for humans to do it if I really wanted it done well.
So I set about doing what I do best: a stress test!
The results were impressive enough that I decided to make my next project automating several tasks so that I could archive and transcribe all of my historical content in bulk.
It was a great holiday project, but once I started traveling again I realized that it was a pain to maintain given that I rarely have access to a beefy CUDA compatible GPU. Then I randomly stumbled across a tweet about "whisper.cpp" which was a CPU optimized version of Whisper. I decided to test it out... along with any other open source transcription projects I could find. Let's dive in!
The Contenders
Coqui STT - this is a fork of Mozilla's DeepSpeech that has been in development since early 2021.
Mozilla DeepSpeech - an open-source Speech-To-Text engine, using a model trained by machine learning techniques based on Baidu's Deep Speech research paper. It uses Google's TensorFlow to make the implementation easier. Looks like it was actively developed from 2017 to late 2020 but has since been abandoned.
Flashlight is a fast, flexible machine learning library written entirely in C++ from the Facebook AI Research and the creators of Torch, TensorFlow, Eigen and Deep Speech. The project encompasses several apps, including the Automatic Speech Recognition app for transcription.
Speechbrain is a conversational AI toolkit based on PyTorch. From browsing their documentation it looks like this is more of a programming library designed for building processing pipelines than a standalone transcription tool that you can just feed audio files into. As such, I didn't test it.
Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multi-task model that can perform multilingual speech recognition as well as speech translation and language identification.
Whisper.cpp is a high performance CPU optimized version of OpenAI's Whisper engine that I tested last year.
Getting Started
All of the (input and output) data used for this project is available in this github repository. In particular, the 10 minute long audio file used as input can be found here.
Right off the bat I noticed that, compared to OpenAI's Whisper engine, all of these other projects are quite limited with regard to what audio signals they can process. It seems none of them can transcribe mp3 files; only 16 kHz wav files. But converting mp3 to wav is fast and simple with FFMPEG:
ffmpeg -i input.mp3 -ar 16000 -ac 1 -c:a pcm_s16le output.wav
Coqui STT v1.4.0
I followed the instructions for the STT command line client that can be found here. First I had to download the "native client" for my OS from the releases page. Next I downloaded the "english huge vocab" model and scorer from here.
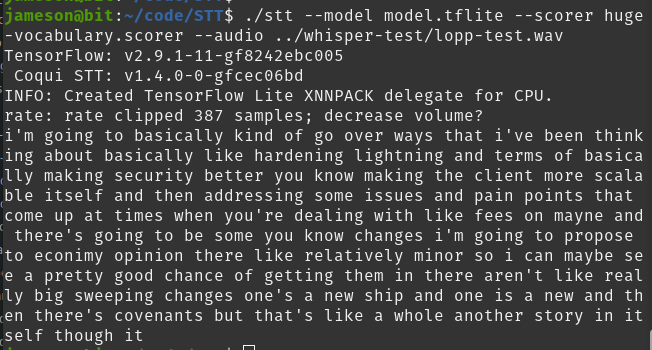
./stt --model model.tflite --scorer huge-vocabulary.scorer --audio roasbeef.wav
It completed transcribing in 2:06. Great performance but... WTF is this gibberish?
"i i'm going to be standing over ways even think about wishing i carnalities of this cremonese erity better than the clan were saleable self and interdiction issues of an point that cannot topedoes like these of manet and the derision archonships be coin but might pedereros with the miners second may be careening they are like really big sweet on changes once in use the catch side and one as you opcode and then there's covenants with haskells in itself the right i quickest may hauiendo ve you like linings cure you one orderly go into onecontaining itself as is now because i can of sunpope know with that is vaguely yet payment channels to connect them you can itacross them i know that like the dust of it mastachelli"
STT output 7100 words when there are only 4400 in my hand-transcribed baseline. And a decent number of them are not even English, such as: cremonese htmsilly chagorihoriennik anemasthe paschendaele entbrausten basiliensis sooslik escandron.
As a control, I recorded the first paragraph of the test input audio with my own voice at normal speed and fed it into STT.
My impression is that it's pretty good at parsing words if the input is of high quality and not spoken too quickly. But it's not good at all when it comes to punctuation. It seems that STT doesn't actually understand the concept of English diction and grammar, but rather it tries to transcribe each syllable separately and then glue them together in the hopes that it's a word. Also, the final result is all one long unending stream of text with no punctuation whatsoever. Not great.
DeepSpeech v0.9.3
Since STT is a fork of DeepSpeech, getting set up is pretty much the same process. I simply downloaded the appropriate native client, model, and scorer from their most recent release. Then I ran the following command:
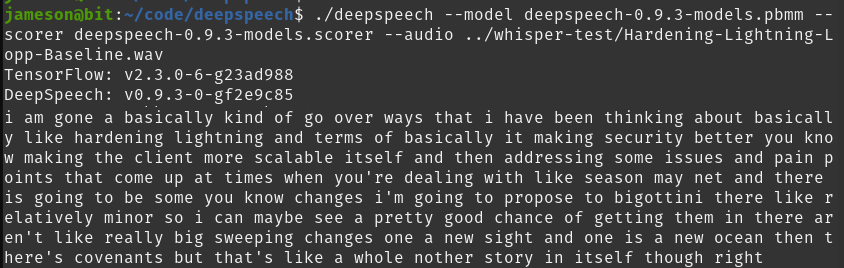
./deepspeech --model deepspeech-0.9.3-models.pbmm --scorer deepspeech-0.9.3-models.scorer --audio roasbeef.wav
It completed transcribing in 3:22. Good performance but... very similar gibberish as Coqui STT. This is not surprising giving that the projects are related.
"tension to his kind of cover was even think about rascality in turn to his clemency better making the climbers halliwell so and interestedness of pinpoint the contagious like these on manet and the garrison i know partington but my peneleos be miners eat may be so presenting in they are like really fixing changes one in you say cassian one is in you ocean then there's confidence with that like a woman misease the right yes i quickened her really go into you know the antinoeus i kind of assume yellow with bayonets"
DeepSpeech performed similarly well on the baseline sample audio I recorded myself.
Flashlight v0.3.2
Flashlight was a pain in the ass, to say the least. Because they don't offer precompiled binaries, I had to figure out how to build it from source. Getting some of the dependencies installed was annoyingly time consuming.
I tried building from source but ended up having to install this dependency separately. Once I did there was a version compatibility issue and I couldn't figure out how to install the older 2.0 version that cmake wanted. So...
Eventually I just followed the vcpkg install instructions which then led me to have to install a different dependency, Intel's Math Kernel Library, via these instructions.
My first install run-through completed but vcpkg told me that MKL was still not installed. After an hour of reading github issues and forum posts and trying half a dozen things, eventually I downloaded the full offline standalone install from Intel. I noticed that if you ran the shell script without sudo it would CLAIM the install worked, but not all of the files would exist under /opt/intel/oneapi. Installing with sudo fixed that. Then I had to run:
source /opt/intel/oneapi/setvars.sh
./vcpkg install flashlight-cpu
After running for nearly an hour, the build failed with a bunch of syntax errors in the Histogram class. Ugh. Looking at Flashlight's open issues I can't help but note that many of them are about build failures. My struggles are clearly not unique.
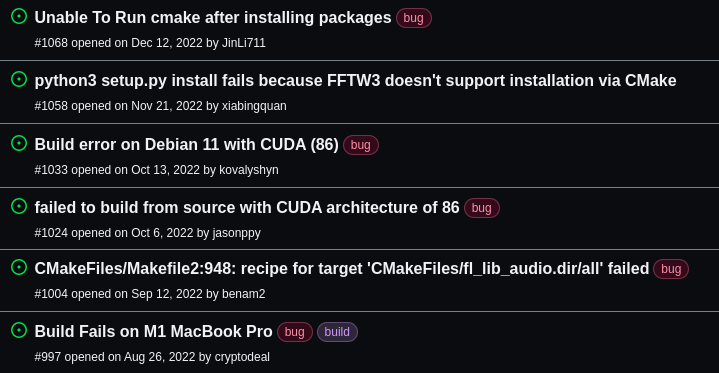
Sorry, Flashlight devs, but you made this process too difficult. Please start providing prebuilt binaries!
Whisper
Whisper's quite simple to set up; you only need FFMPEG and pip installed. At first I didn't re-run my tests from 2 months prior since I still have the results on hand. You can read my earlier blog post if you want the details - it was also comparing different CPUs and GPUs.
But then it was pointed out to me that a code change that made massive performance improvements was merged shortly after I ran my original tests. So I updated whisper and re-ran the test with each model like so:
whisper ./roasbeef.mp3 --language en --model small
Whisper took a while to process the 10 minute input mp3.
Small model: 19:17
Medium model: 56:00
Large model: 1:49:00
Whisper.cpp v1.0.4
This software was the simplest to get running. After cloning the github repository, first I had to download and build the models I wanted to test by running these commands:
bash ./models/download-ggml-model.sh small.en
bash ./models/download-ggml-model.sh medium.en
bash ./models/download-ggml-model.sh medium
bash ./models/download-ggml-model.sh large
makeThen running against a wav file is as simple as:
./main -t 6 -m models/ggml-small.en.bin -f roasbeef.wav
By default the software is configured to use 4 threads and 1 processor. I played around with a bunch of different thread and processor settings. Increasing the number of processors always resulted in worse performance, though moderate increase of the threads helped performance. Unsurprisingly, the best performance I found was to set the number of threads (the 't' parameter) to the number of physical cores (6) on my processor.
Small.en model: 3:45 with 4 threads
Small.en model: 3:04 with 6 threads
Small.en model: 3:31 with 8 threads
Small.en model: 3:31 with 12 threads
Medium.en model: 8:55 with 6 threads
Medium model: 10:02 with 6 threads
Large model: 18:18 with 6 threads
Oddly, I noticed that the output from the medium.en model was very different from all the other models - it was missing commas and line breaks between paragraphs, so I filed an issue and used the full language medium model for my accuracy testing. It turns out that the inconsistent output format is a known problem that simply one of the nondeterministic attributes of using Whisper's AI engine.
Performance Results
Amazingly, whisper.cpp with the small model is 6X faster on a 6 core Intel i7 CPU as OpenAI's Whisper!
Accuracy Results
I used this diffchecker tool to easily visualize and count the differences between my hand transcribed baseline output and the output from the different transcription software.
Deepspeech: 7.3%
STT: 14.5%
Whisper.cpp (small.en model): 95.2%
Whisper.cpp (medium model): 91.5%
Whisper.cpp (medium.en model): 94.4%
Whisper.cpp (large model): 98.8%
But wait! Most of the "inaccuracies" from the whisper.cpp small and medium output were actually the removal of filler words that contributed nothing to the transcript and removing them actually improves the transcript legibility. How does the accuracy measure improve when we don't count the removal of extraneous instances of "like," "you know," and "kind of?"
Whisper.cpp (small.en model): 98%
Whisper.cpp (medium model): 97.7%
Whisper.cpp (medium.en model): 94.4%
Whisper.cpp (large model): 98.8%
This is a particularly interesting phenomenon that did NOT occur when using OpenAI's Whisper software.
Conclusions
Remember that this test is of a single audio stream that was chosen specifically BECAUSE it's difficult to parse, even for humans.
When comparing STT with DeepSpeech it's unsurprising that the actively developed project (STT) is both more performant and more accurate than the abandoned project. And sure, while those projects have far better performance than any of the Whisper software, their accuracy and reliability is far lower, at least on more challenging audio inputs. I'd argue that the trade-offs are not worth it. They also appear to be more primitive, with little to no understanding of syntax and grammar. Whereas I've observed whisper actually clean up grammar and create transcripts that are MORE legible than they would be if it perfectly transcribed every single word.
From my discussions with the whisper.cpp developer, it can be pretty difficult if not impossible to understand why the output for a given audio stream with a given model exhibits certain characteristics. Since the output's characteristics can be unpredictable, I'm sure that there are other types of audio streams for which the accuracy differences between the different models will not match my findings with these tests.
But it's quite clear that the best "bang for your buck," if you're looking to quickly transcribe poor quality / difficult-to-interpret audio streams on a consumer grade CPU, is whisper.cpp with the small model. If you want even better accuracy at the expense of legibility because it will include filler words, use whisper.cpp with the large model.




